


Guest post by Adam Judelson, a former Palantir head of Product that owns a product agency helping companies achieve transformative visions, whilte hosting the Emergent podcast and newsletter.
AI agents can add superhuman capabilities to your product, but what is the intuition for when to incorporate them into your strategy?
Put simply, AI agents generate maximum value when we place them wherever modestly intelligent humans existed in workflows in the past. Agents gain power particularly when chained together, used in concert, or when forward-deployed. An agent can live on your computer to interact with your file system, on your social media account, deep inside a factory assembly line, on a satellite, or wherever that human-like quality is required for product success.
For those new to the buzz around agents, they are what they sound like: miniature GPTs that you can place inside complex architectures to perform cognitive tasks that machines have historically struggled with. They can operate autonomously, in clusters with other agents, or in a hybrid model combined with existing microservices. They leverage generative AI, so at a minimum, they can:
Make a decision or judgment
Summarize text or other content
Analyze data or evaluate
Generate text, images, or even systems
Take actions as a real user (for example, make a purchase or send an email)
Generative AI is best for challenges requiring a modicum of judgment, whereas traditional services are superior for tasks that require certainty and precise instructions.
With this high-level heuristic in mind, let’s explore thinking models that could advance your product, moving from the least sophisticated to the most advanced. Along the way, we’ll provide examples and diagrams to illustrate how each might work across six varied use cases that we’ve named Inspectors, Conductors, Assembly Lines, Hydras, Missions, and Mobius Cycles.
Inspectors
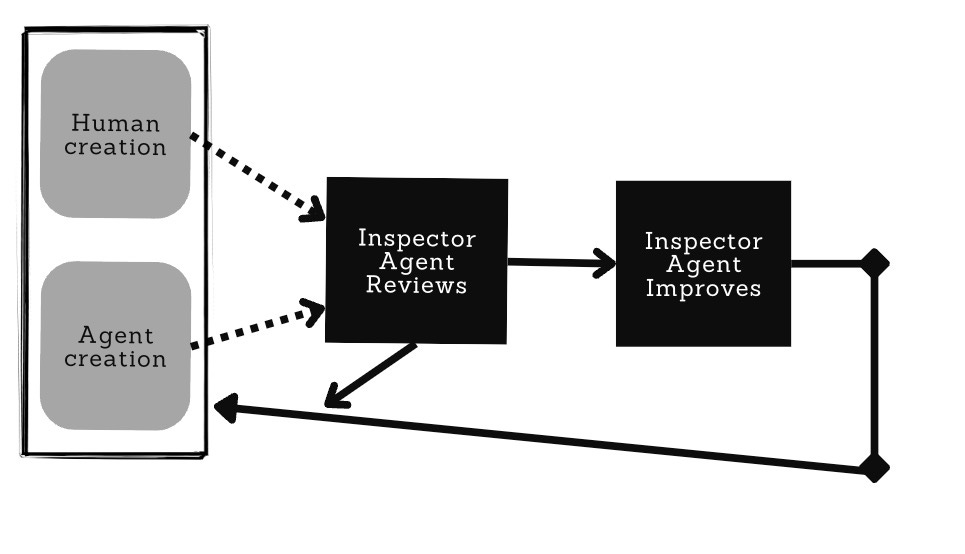
Inspector agents excel at handling inconsistent human outputs, enforcing standards, or by providing qualitative critiques to ensure that work meets or exceeds expectations. In short, they can act as a quality-control gate. I like to think of this set of use cases as giving the agents a persona and then implanting them into a system or process where quality control or stress testing is needed. For example, a customer service system for a Fortune 500 company requires care and feeding across many dimensions:
How technically competent were the representatives?
Did they use appropriate soft skills in dealing with customers?
Are they respecting company policies and processes?
A traditional human manager would have to tackle these challenges themselves, but a series of agents can operate on the manager’s behalf to spot concerning interactions (and eventually to monitor non-human agents too!). Imagine the following interaction among a hypothetical CVS pharmacy customer, a CVS customer service representative, and a Quality Control AI agent.
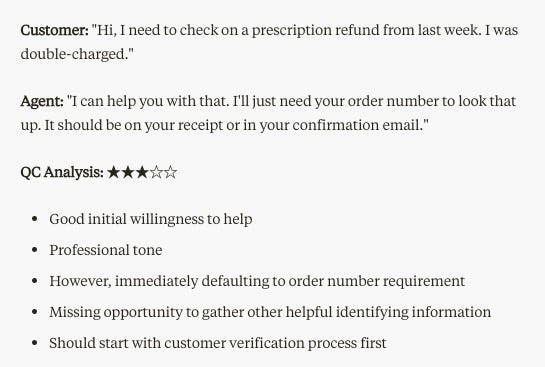
The above scenarios were scripted and analyzed 100% by AI agents, and you can see each taking responsibility for acting as a particular persona, providing valuable context for the customer service department in terms of how they want to train their human or AI agents to act. Just as we used to bake certain mores into a company culture, we now need to bake these into the AI to get the customer experience and personality we desire.
Stress testing is another strong use case for agents. Whenever a human or an AI comes up with a result, a stress-testing agent can act as a critical bystander trying to elevate the quality of what was produced. Take, for example, the following AI-generated summary of the Los Angeles Dodgers’ World Series win this year:

Let’s create and dispatch another agent as a sports news expert whose job it is to critique and improve on these clips. The agent correctly notices the lack of a score, no mention of the pitchers, very little sense of the actual action, and more. Here is an improved version after the writer agent stress tested and improved upon the summary. Unfortunately, our agent still needs some training, since the Dodgers did win much more recently than 1988, but the draft is substantially improved. A fact-checking agent is probably needed too!

While these agents are presented together in this example, in a live production system each might occupy different space in different or complementary systems. The choice is up to the product leaders and the system architects and will depend in large part on how often each agent might be reused in different contexts.
The inspector model excels when:
The results of an ongoing process have high variance in quality
The quality is best critiqued by a human, and therefore encoded in an agent
The results need to conform to certain standards, but where those standards require ongoing judgment
Conductors
Increasingly sophisticated product systems can rely on AI agents to serve as the Conductor in Chief, orchestrating and selecting actions based on the content of the request. Conductor use cases tend to be ones in which the product receives a natural-language request from a user, and the conductor agent must determine, based on the information supplied in the request, where to route it, and then recompile the outputs from each part of the system into one coherent response for the end user.
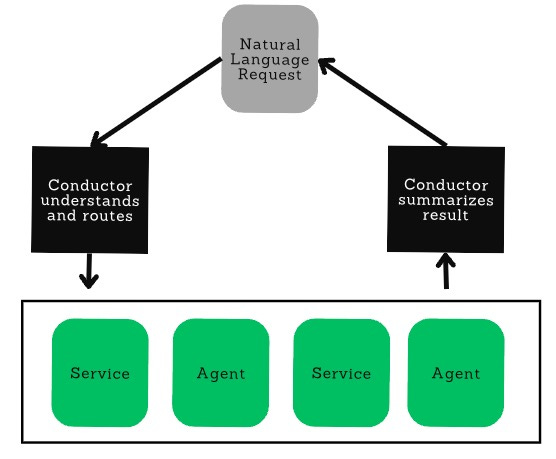
One company I advise, Danti.ai, provides customers with a search interface for finding hard-to-access content related to places on Earth—for example, satellite imagery, the locations of shipping vessels, property reports, and much more. Each data source is accessed differently, and rarely is an LLM-based search the right answer for queries where high precision is required in the response, so a conductor agent is needed to determine when to invoke traditional, pre-existing tools that do not use generative AI or to dispatch other agents.
For example, when a user asks a question like “What homes were damaged in Tampa in the recent storm?” the conductor must use its judgment to infer that news data, satellite imagery, and severe-storms data sources are ideal for answering this question. The conductor must make that selection (Anthropic calls this paradigm “tool use”), request the news, use it to find the storm in question and its date and exact location, and then form a query to find satellite imagery based on dates and latitudes and longitudes so the user can receive a result set that answers the question. Meanwhile, the conductor must also meaningfully combine the disparate answers into one user-facing “result” that summarizes what it found.
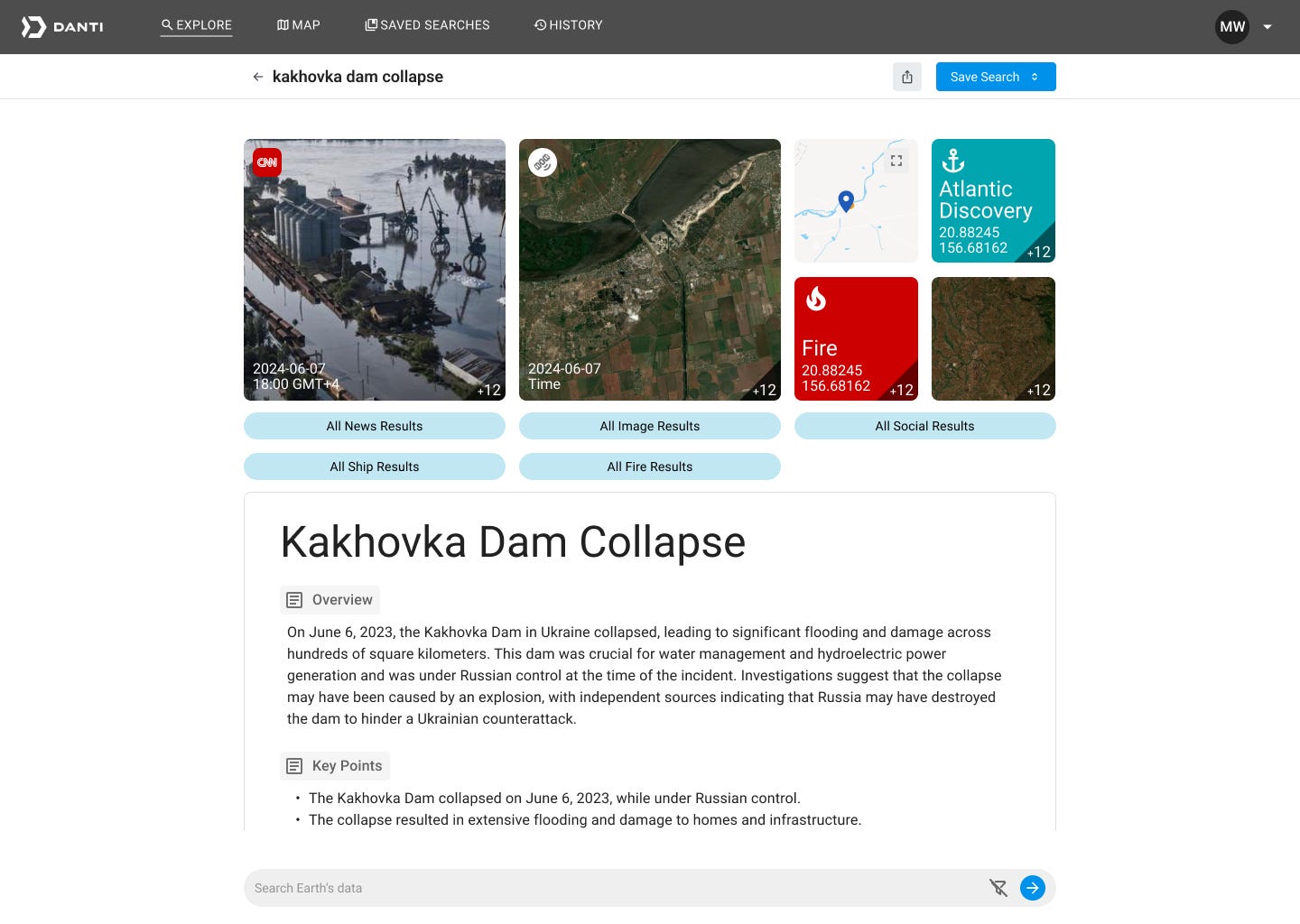
Screen capture from danti.ai during a search for a dam collapse incident in Ukraine showing news, satellite imagery, shipping information, and much more
The conductor model excels when:
Your inputs are natural-language requests from humans or other LLMs
The answer or result requires accessing many different resources but frequently not all of them, and where judgment is required to determine which ones
The result requires judgment to recombine
Assembly Lines (aka Extended Conductors)
Sometimes the task is finite, such as in the search example above (query in -> result out); however, there is a powerful variant of the conductor model that I like to call the “assembly line” because it involves an open-ended set of actions toward an ongoing persistent goal. It’s easiest to imagine this paradigm as an agentic system that is responsible for keeping an assembly line on track. Let’s take the following literal example of a drone production assembly line:
A pre-existing quality-control automation throws “Error 5521” while a drone is being built.
The agent checks the production history archives, finds the error code, and learns that there is a 63% chance that this is due to a loose cable.
The agent decides to capture an image of the issue and deploys a camera robot to verify the situation.
The agent receives the image and sends it to a quality-control plus computer-vision agent, which assesses that the issue is the result of poor attachment of the balance plug to the power distribution board.
An assembly-line-routing agent re-routes the assembly back to the power technician.
The agent creates a defect ticket and assigns it to the manufacturing engineer.
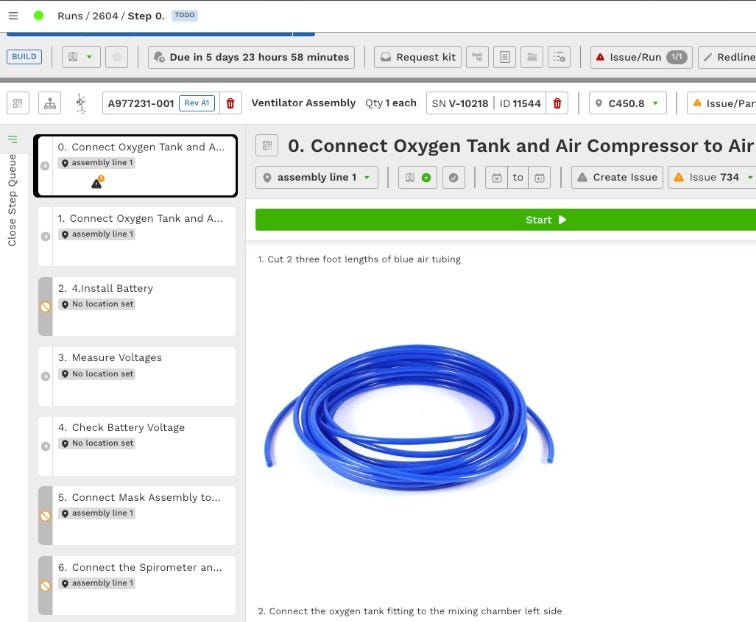
An assembly-line procedure from First Resonance’s ION product, which acts as an operating system for advanced manufacturing factories
The assembly-line model excels when:
There is an ongoing goal that must be maintained over the course of a complex process (in this case, keeping the assembly line running)
The process can be monitored in/at one or many places
Issues will arise in pursuit of that goal that require judgment to resolve
There are tools available to the agent to pursue resolution
Hydras
The AI agent world often mimics the human world, and, much as humans specialize and gain knowledge from their experiences, so too can agents. Similar to humans, often a superior outcome is achievable only when we collaborate, so the “hydra” refers to use cases when training multiple personalities that each act like humans with different interests helps us to sort out the best plan of action. This can be particularly advantageous when the user of the product would benefit from seeing how the sausage is made and might want to see the spikiest viewpoints and not just the final summary or “average” result.
Take, for example, a Board Meeting preparer system. A naive approach to preparing for such a presentation is to toss your deck into an LLM such as ChatGPT and ask for feedback or ask it to play a few roles. Much more powerful is tailoring a specialized investor agent, a marketing agent, a sales agent, a product agent, an engineering agent, and so on, and then having each critique the plans with data and experience to back up their specialities trained over time. Better yet, in addition to this critique, it can be advantageous to set the agents up to have a conflict with one another that they then have to also resolve, giving you crucial insights into how to navigate these treacherous waters and thread a needle through the solution.

The hydra model excels when:
Customers need to make important decisions where extra time is worth the tradeoff
Where many subject matters come together to impact the decision
Where data and experience exist to inform multiple “personalities” and their biases
The Mission
Mission use cases are ones in which a system must take on a new or novel goal each time it is used and needs to make a series of planning and execution decisions to achieve this. Imagine trying to offload the planning and booking of an entire vacation end-to-end to an agentic system. Or think about a robotic arm in space that needs to fix a broken solar panel on a space station, and tomorrow it needs to unload a new shipment of resources. A more “down to Earth” example is autonomous drone reconnaissance. Suppose we want to ask a drone, “Is there any new construction along the river within one mile of here?” This is a highly specialized mission. Agents might operate as follows:
An agent to plan the mission and recruit the other agents below
An agent to interpret the question and parse out the location and target
An agent to plan the flight path within the constraints and communicate with the drone’s flight software
An inspector agent to test the flight path against flight rules from the FAA
An agent to check if the weather is suitable and to select the time for the mission
An agent to trigger the drone’s camera when the drone is along the river
An agent to interpret the images and identify construction
An agent to make time-lapse image comparisons
An agent to summarize the results
This setup highlights how multiple specialized agents work in unison to achieve complex outcomes—each agent doing what it does best while collectively achieving the mission goal.
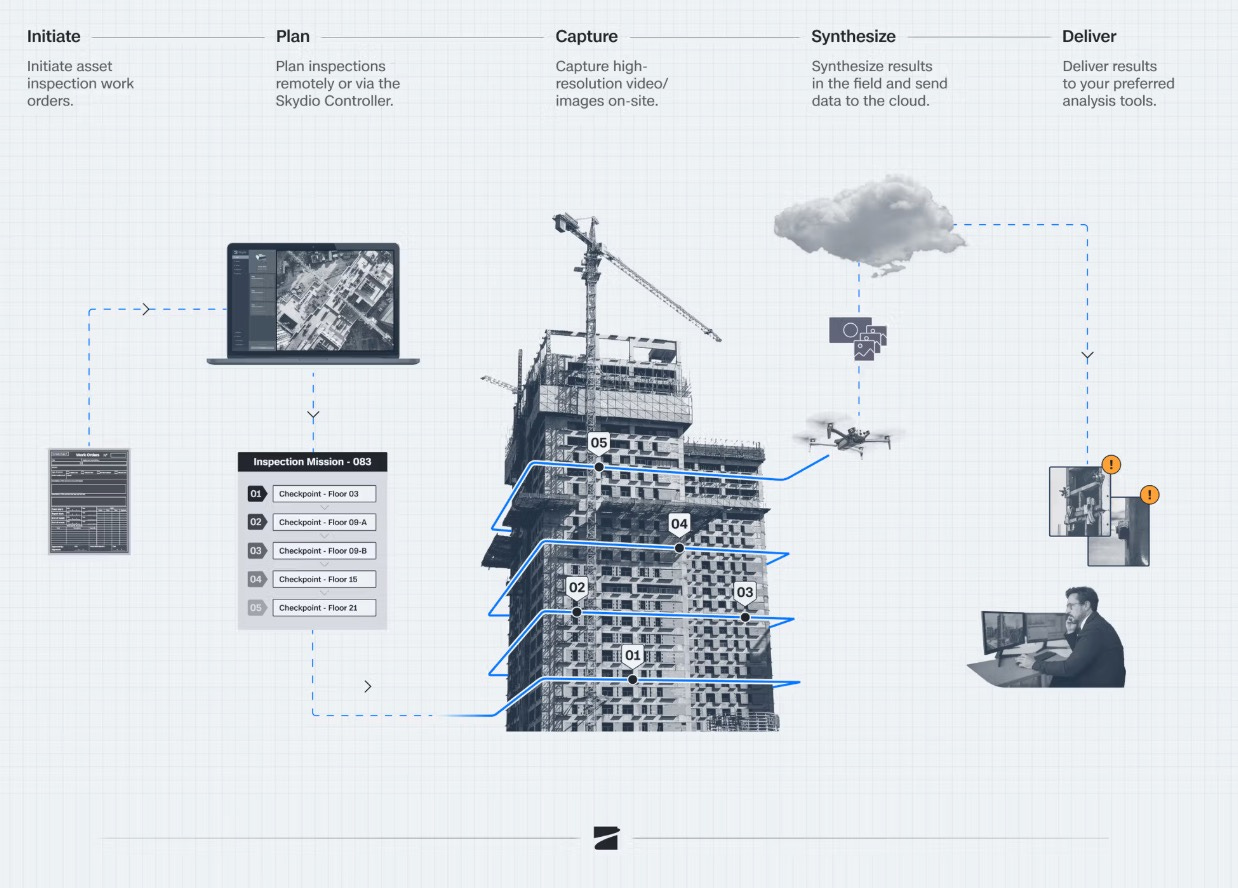
Diagram of a Skydio autonomous drone inspection breakdown
The mission model excels when:
An open-ended task must be completed that requires planning and coordination
There are a large series of steps that often do not proceed in a specified order
Possibly an interplay between hardware and software
Mobius Cycles
A final variant is what we’re calling Mobius cycles, named to communicate the ongoing cyclical nature of the tasks, and yet they do not always arrive back at the same starting point. These are use cases where we might cycle through the same or very similar sets of tasks, and will do so repeatedly to achieve a goal. This requires thoughtful agent orchestration where multiple agents interact seamlessly, like a symphony of specialized players. Writing code without intervention from a human is a great example, and Devin showcases this pattern wonderfully. Devin is an agentic system that takes a basic prompt for what to build with software, puts it together in code, tests it, corrects issues, deploys it, and even finds bugs and improves the code over time. It is constantly returning to the same cycle of actions, but it is exercising judgment about which order and when and is even evaluating the results continuously.
Thinking in specifics, we can consider a coding example in which a bug-fixing agent corrects faulty code while an additional quality-control agent checks and enhances the readability and performance of that fix. By stringing these together, each agent takes responsibility for a specialized part of the work, making the output more robust and reliable. Then the code is periodically exercised and run, the output is assessed against the specification, and the process is repeated to continue to improve it.

Visualization from the robotic arm and computer vision company picknik.ai/space
The Mobius model excels when:
Repeated cycles of tasks are required, with iterative refinement and improvement over time
Continuous processes exist, such as coding pipelines or testing loops
The task demands dynamic judgment about task order, timing, and evaluation of results but within a semi-defined construct
A word of excitement, and caution
We’ve explored a lot of nuanced and powerful use cases for agents. Remember, they are far more than simply using a single LLM in your product—they are new workflows that are empowered by the ability to chain together complex structures of autonomous agents with existing systems to achieve a particular goal that demands some amount of elevated reasoning at multiple points in the system. They are often forward-deployed to do the work, and they excel when used in concert, or where a modicum of human judgment is required.
As a result of these advances, this is the most exciting time for product since the invention of the internet. However, AI agents are just that—they are AIs trained on what humans before them have done, and some of those humans were not the most trustworthy creatures. Agentic systems carry the promise of massive productivity gains, but they also carry the near guarantee of accidental information leaks, wild execution of decisions without a human in the loop, data corruption, or truly just about everything envisioned in every dystopian robot movie. So please proceed with caution, and do invest in protecting sensitive data, people, and critical infrastructure as a first-class citizen when experimenting with these amazing creations.
This is really great. I love how this answers “what can we use agents for”. I would like to get an opinion or thought piece on the “should we use them” from an ethics and forecasting perspective. I’m sure you have some really interesting insights.
Very great deep dive